Agno 框架的部署与调优
2026-05-16
agno:(原 Phidata)是一个开源、轻量且高性能的生产级 AI Agent(智能体)开发框架。它旨在解决 LangChain 等传统框架过于臃肿、难以落地生产的问题。
极简构建:用少量 Python 代码即可为 Agent 注入指令、长期记忆和 RAG 知识库,并支持多个 Agent 组合成多智能体团队协同工作。
自带生态:内置 100+ 工具包(如 Web 搜索、SQL 数据库),原生支持 Slack、Notion 等上下文输入及 MCP 协议。
面向生产:它不仅是 SDK,还提供高性能运行时(处理高并发与会话隔离)和管理控制台(支持实时追踪、调试和审计)。
简而言之,Agno 砍掉了繁琐的过度封装,让开发者能以极高的效率,构建出稳定、可监控的企业级 AI 应用。
之前搭建的光遇面板最近进行了一次迭代升级 加了一个回归先祖的百科🤓👉https://sky.lazyrain.xyz/ancestors (爬的BWIKI)因为是定时爬虫 所以有时候避免不了分析数据 刚好最近在Linuxdo看到了有佬推荐这个Agent框架 学习了尝试自己做一个Agent来分析爬虫数据 于是就有了这篇记录。
控制中心 (Agent 宿主机):Mac 本地环境。
被控节点 (资源/算力侧):Debian 服务器(位于局域网/内网,通过 SSH 反向隧道进行跨网络节点联动)。
核心框架:Agno (前身为 Phidata),一款主打极简、高效、低内存占用的开源多模态 Agent 框架,负责编排 LLM、Memory 以及各种底层 Toolkits。
目标:在 Mac 本地搭建起稳固的 AgentOS 运行时环境,为后续挂载远程 Debian 服务器上的复杂工具(如 PostgreSQL 数据库、MinerU 解析节点等)打下基础。
我希望这个Agent能够实现:
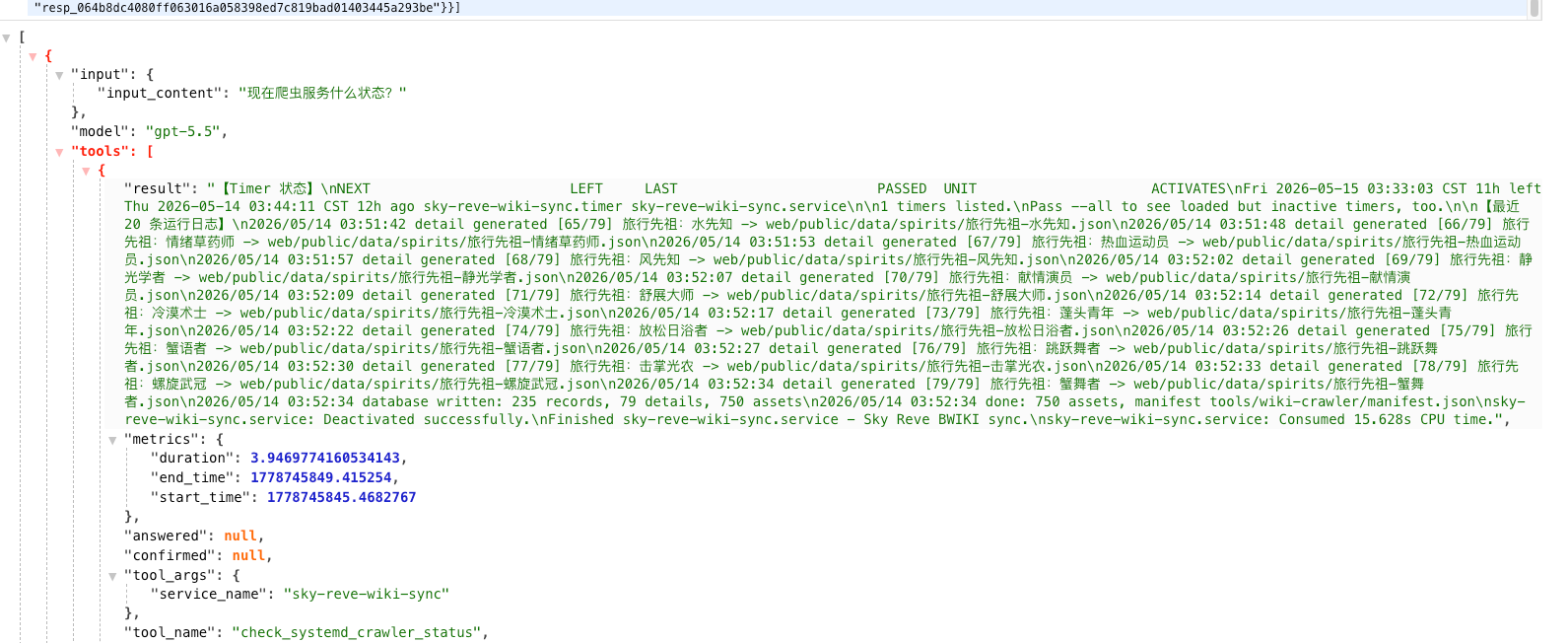
检查 Debian 服务器上 sky-reve-wiki-sync.service 服务和 timer 的状态与最新日志。
在 Debian 服务器上执行任意 shell 命令并返回输出。
当你需要搜索服务名、检查目录或查看进程时,请使用此工具。
一些思考:
既然需要让Agent在Debian上查询爬虫服务的日志那么就可以用 paramiko库的SSHClient来连接服务器
用传统的ssh连接服务器需要交互式的输入密码 可以在Debian中生成Private Key来让 Agno Agent 通过密钥实现无感知的自动化登录,还能平时在其他终端随时用密码连上去排查问题
关于Context上下文记忆 如果Agent没有记忆那么我每次使用都得告诉他当前项目在服务器中的什么地方 叫什么名字 代码的原理是什么 不然就需要消耗大量的token来自行推理 效率不高 很显然这不是我想要的 所以我们可以给他接入一个数据库来保存会话的记忆 我这里用的是postgresql
按照官方的示例是需要启动Agno后在他的官方网页中填入本地服务的接口来使用的 我觉得太麻烦了 我自己本地起个服务还得到你官网上来连接使用 于是我找到了Agent-ui这个项目
https://github.com/agno-agi/agent-ui 他提供了一个脚手架可以在本地起一个交互式的web UI来使用 就不需要你在代码中显示的描述提问
具体代码实现:
import paramiko from agno.agent import Agent from agno.os import AgentOS from agno.models.openai import OpenAIChat from sshtunnel import SSHTunnelForwarder from agno.db.postgres import PostgresDb import uvicorn # --- 配置参数 --- SSH_HOST = "192.168.112.79" SSH_USER = "root" PKEY_PATH = "id_ed25519_localDebian" # 你的私钥路径 DB_IP="192.168.112.79" DB_PORT=5432 DB_USER = "root" # 你的数据库用户 DB_PASS = "xxxxx" # 这里需要注意 如果你的数据库密码中包含@ 请你转义成%40来代替@ 不然会报错 DB_NAME = "root" # 你的数据库名字 # Docker 映射到 Debian 宿主机的端口,通常是 5432 # REMOTE_DB_PORT = 5432 # MODEL_ID="gpt-5.5"# 或者是你的 CPA 支持的其他模型名称,比如 claude-3-5-sonnet-20241022 # API_KEY="sk-xxxxxxx" # BASE_URL="https://xxxxx/v1" # 记得加 /v1 MODEL_ID="GLM-5-thinking"# 或者是你的 CPA 支持的其他模型名称,比如 claude-3-5-sonnet-20241022 API_KEY="xxxxxxxx" BASE_URL="https://xxxxxx/v1" # 记得加 /v1 # 1. 显式配置你的中转大模型 cpa_model = OpenAIChat( id=MODEL_ID, # 或者是你的 CPA 支持的其他模型名称,比如 claude-3-5-sonnet-20241022 api_key=API_KEY, base_url=BASE_URL # 记得加 /v1 ) def check_systemd_crawler_status(service_name: str = "wiki-crawler"): """ 检查 Debian 服务器上 sky-reve-wiki-sync.service 服务和 timer 的状态与最新日志。 """ SSH_HOST SSH_USER PKEY_PATH try: client = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(SSH_HOST, username=SSH_USER, key_filename=PKEY_PATH) # 1. 查 Timer 下次触发时间 timer_cmd = f"systemctl list-timers {service_name}.timer --no-pager" stdin, stdout, stderr = client.exec_command(timer_cmd) timer_info = stdout.read().decode('utf-8').strip() # 2. 查 Service 最近运行状态和报错 log_cmd = f"journalctl -u {service_name}.service -n 20 --no-pager --output=cat" stdin, stdout, stderr = client.exec_command(log_cmd) log_info = stdout.read().decode('utf-8').strip() client.close() return f"【Timer 状态】\n{timer_info}\n\n【最近 20 条运行日志】\n{log_info}" except Exception as e: return f"SSH 执行命令失败: {str(e)}" def run_debian_command(command: str): """ 在 Debian 服务器上执行任意 shell 命令并返回输出。 当你需要搜索服务名、检查目录或查看进程时,请使用此工具。 """ SSH_HOST SSH_USER PKEY_PATH try: client = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(SSH_HOST, username=SSH_USER, key_filename=PKEY_PATH) # 直接执行 Agent 传过来的任何命令 stdin, stdout, stderr = client.exec_command(command) output = stdout.read().decode('utf-8') error = stderr.read().decode('utf-8') client.close() return output if output else error except Exception as e: return f"命令执行失败: {str(e)}" # --- 建立自动化隧道与 Agent 启动 --- def start_interactive_agent(): # 1. 创建并启动 SSH 隧道 # 把远程服务器的 localhost:5432 映射到本地的一个随机可用端口 # with SSHTunnelForwarder( # (SSH_HOST, 22), # ssh_username=SSH_USER, # ssh_pkey=PKEY_PATH, # remote_bind_address=('127.0.0.1', REMOTE_DB_PORT), # local_bind_address=('127.0.0.1', 0) # 0 表示让系统自动分配空闲端口 # ) as tunnel: # print(f" SSH 隧道已建立: Mac:127.0.0.1:{tunnel.local_bind_port} -> Debian:127.0.0.1:{REMOTE_DB_PORT}") # 2. 配置基于隧道的数据库连接 # db_url = f"postgresql+psycopg2://{DB_USER}:{DB_PASS}@127.0.0.1:{tunnel.local_bind_port}/{DB_NAME}" db_url = f"postgresql+psycopg2://{DB_USER}:{DB_PASS}@{DB_IP}:{DB_PORT}/{DB_NAME}" agent_db = PostgresDb( session_table="agent_memory_sessions", db_url=db_url ) # 3. 初始化带有“持久化记忆”的 Agent sre_agent = Agent( name="SkyReve SRE", # 新增:有了名字,UI 才能展示它 id="sky-reve-sre-01", # 新增:给它一个固定的后台 ID model=cpa_model, db=agent_db, session_id="sky-reve-sre-session-v1", add_history_to_context=True, # 正确参数:将历史加入上下文 num_history_runs=10, # 正确参数:保留最近5轮对话 tools=[check_systemd_crawler_status, run_debian_command], description="你是 sky-reve 项目的专属运维大脑。", ) agent_os = AgentOS( agents=[sre_agent], ) app = agent_os.get_app() uvicorn.run(app, host="127.0.0.1", port=7777, reload=False) if __name__ == "__main__": start_interactive_agent()


当你调用Agent让他进行任务时 他会在你配置的数据库中自动生成表 并将记忆储存起来 他们看起来像这样:

我们可以把这些表按功能分为四大类,让你一眼看懂它们是干嘛的:
一、 记忆与认知系统(最核心的脑区)
这部分表负责让 Agent 变得“聪明”且“懂你”。
agent_memory_sessions:(这是你代码里手动指定名字的表)。它存放的是每一次完整对话的流水账(Messages)。相当于 Agent 的“短期工作记忆”。agno_memories:长期记忆表。如果你开启了enable_agentic_memory=True,Agent 会自动从对话中提取关键事实(比如“主人的项目叫 sky-reve”、“服务器是 Debian”)碎化存进这里。agno_learnings:学习表。比 Memories 更高级,用来存放 Agent 在多次执行任务后总结出来的“经验法则”或工作流偏好。agno_knowledge:知识库表。如果你以后给 Agent 挂载了文档库(比如把一堆运维手册 PDF 喂给它),它会在这里建立文件和向量数据库的关联索引。
二、 权限与风控系统(安全护栏)
agno_approvals:审批工单表。记得我们之前聊过Workspace工具里有confirm=["shell"]吗?当 Agent 想要执行危险命令时,它会在这里生成一条待审批记录。你在 UI 上点了“同意”,这条记录状态更新,命令才会被放行。
三、 OS 调度与度量系统(内核后台)
这部分表证明了它具备真正操作系统的调度能力。
agno_metrics:监控与账单表。记录每一次大模型请求消耗了多少 Token、花了多少毫秒、调用了哪些工具。这是你用来监控 CPA 账单的“仪表盘数据源”。agno_schedules&agno_schedule_runs:定时任务表。Agno 支持通过自然语言设定定时任务(例如:“以后每天早上 8 点帮我检查一次爬虫日志”),这些 Cron 任务和它们的执行历史就存在这两张表里。agno_eval_runs:评测记录表。如果你想对 Agent 的能力进行自动化考试/跑分(Eval),成绩单会存在这里。
四、 组件注册表(驱动管理器)
就像 Windows 的注册表一样,用来管理所有的虚拟硬件。
agno_components/agno_component_configs/agno_component_links:这三张表是 AgentOS 的骨架。当你在 UI 里点击创建、修改 Agent,或者把某个特定的 Tool 分配给某个 Agent 时,这些配置信息和相互的绑定关系(Links)都会序列化存在这里。agno_schema_versions:版本控制表。框架自己用的,用来记录当前数据库的结构版本,以后你升级 Agno 库时,它靠这个表来决定是否需要执行数据库热更新。
我们打开agent_memory_sessions看看他里面的数据是怎么样的:

我们把JSON格式化一下就可以一目了然的看出他是怎么储存 对话记忆以及模型之类信息的